SIMD (Single Instruction, Multiple Data) ,本质上就是一条指令同时处理多个数据,旨在实现数据级并行 (Data Level Parallelism)。
一个简单例子是向量加法。传统方式是用循环来对向量中每一对分量求和:
for (int i = 0; i < NUM_ELEMS; i++) {
sum[i] = a[i] + b[i];
}
从算法层面讲,这已经是最优解了。但当考虑到更底层的原理时,还有很大的优化空间。
仔细分析循环,可以发现对于每个分量,都需要做以下工作:
- 迭代开销(计数器增加,条件跳转等)
- 把
a中的分量从内存(缓存)中运到寄存器 - 把
b中的分量从内存(缓存)中运到寄存器 - 用运算单元执行加法
- 将结果从寄存器中运回内存
优化程序性能,无非就是从这几个点下手。
对于第一点,向量有多少分量,for循环中的比较和自增就要做多少次。但如果把数据分成几组,每组作为一个整体运算,迭代开销就会成倍的减少,这就是循环展开(Loop Unrolling):
int i = 0;
for (; i <= NUM_ELEMS - 4; i += 4) {
sum[i] = a[i] + b[i];
sum[i + 1] = a[i + 1] + b[i + 1];
sum[i + 2] = a[i + 2] + b[i + 2];
sum[i + 3] = a[i + 3] + b[i + 3];
}
for (; i < NUM_ELEMS; i++) {
sum[i] = a[i] + b[i];
}
循环展开前,程序需要进行NUM_ELEMS次迭代;循环展开后,迭代次数减少到了大约NUM_ELEMS / 4的水平。
循环展开减少了迭代开销和分支预测压力,但每次迭代还是做了四次运算,ALU 在每一时刻只能处理一对数字。观察循环体,每次运算都是取两个数据做加法,而且被分成一组的数在内存中都是连续的。如果有一个大寄存器,一次性可以存 $N$ 个数,从内存取数据操作的次数理论上就会减少到原来的 $1/N$。更进一步,如果能在这个大寄存器里做加法,运算单元的执行次数理论上也会减少到原来的 $1/N$。
这就是 SIMD 的基本思路。其中的大寄存器,叫做向量寄存器。
过去几十年,Intel 的处理器在市场占主导地位,它在 SIMD 指令集领域做的工作如今依然是最被广泛应用的。
Intel 在 1999 年随 Pentium III 处理器发布了 SSE (Streaming SIMD Extensions) 指令集,引入了 8 个 128 位 XMM 寄存器;在后来的 x86-64 环境下,XMM 寄存器扩展为%xmm0-%xmm15 共 16 个。一个 128 位的寄存器可以存 4 个 32 位数据。
AVX (Advanced Vector Extensions) 在2011年随 Sandy Bridge 架构发布,向量寄存器扩展到 256 位 (%ymm),但主要支持浮点数运算。
2013年,AVX2 随 Haswell 架构发布,将 256 位支持扩展到了整数运算。
而 2017 年前后进入主流产品视野的 AVX-512 将向量寄存器扩展到了 512 位 (%zmm)。不过 AVX-512 的部署一直比较复杂:Intel 此前在部分 Xeon 和 Core X 系列上提供过支持,但在 Alder Lake 这一代消费级大小核桌面平台上基本移除了官方支持;AMD 也在后续 Zen 4 消费级处理器上提供了 AVX-512。
回过头看我们的向量加法,假设int是32位的,那么256位的%ymm寄存器可以一次性装 8 个int值,SIMD 版本现在就可以这样写:
int i = 0;
for (; i < NUM_ELEMS / 8 * 8; i += 8) {
// 把 a[i : i + 7] 一次性装进 %ymm0
// 把 b[i : i + 7] 一次性装进 %ymm1
// 计算 %ymm0 和 %ymm1 的和,结果存入 %ymm2
// 将结果一次性放进 sum[i : i + 7]
}
for (i = NUM_ELEMS / 8 * 8; i < NUM_ELEMS; i++) {
sum[i] = a[i] + b[i];
}
其中NUM_ELEMS / 8 * 8是不大于NUM_ELEMS的最大可以被 8 整除的数。
AVX 提供了专门的汇编指令来完成这些工作。“一次性装进寄存“对应vmovdqu指令,其中v是 AVX 指令的前缀,movdqu表示 Move Double Quadword Unaligned,它可以直接在任意内存地址和%ymm寄存器之间移动 256 位的数据。既然有 “Unaligned” 版本,自然也有 “Aligned” 版本:vmovdqa,它要求内存必须对齐,但会带来微小的性能提升。
实际上,Double Quadword 指的是 128 位(SSE 时代的命名),AVX 扩展到了 256 位,但沿用了 Double Quadword 的名字
假设:
a的地址在%rsii的地址在%rax
那么"把 a[i : i + 7] 一次性装进 %ymm0"用汇编表示就是:
vmovdqu (%rsi, %rax, 4), %ymm0
(%rsi, %rax, 4)是经典的 x86 寻址方式,它计算a + i * 4,即a[i]的地址。
假设:
b的地址在%rdx
那么"把 b[i : i + 7] 一次性装进 %ymm1" 用汇编表示就是:
vmovdqu (%rdx, %rax, 4), %ymm1
求和需要用到另一个 SIMD 指令:vpaddd,其中p表示Packed,add表示加法,d表示 Doubleword,即32位。它可以对 8 个 32 位整数通道并行做加法:
vpaddd %ymm0, %ymm1, %ymm2
我们在 Linux 上用一个汇编程序的例子来仔细观察指令的行为:
# simd_int.s
.section .data
.align 32 # 显式对齐
array_a: .long 10, 20, 30, 40, 50, 60, 70, 80 # .long: 32 位整数,对应 C 中的 int
.align 32
array_b: .long 1, 2, 3, 4, 5, 6, 7, 8
.align 32
result: .fill 8, 4, 0 # 8 个 4 字节空间,初始化为 0
.section .text
.global _start
_start:
# 1. 加载 8 个整数到 %ymm 寄存器
vmovdqu array_a(%rip), %ymm0 # 非对齐版本依然可以操作对齐数据,但会损失微小性能
vmovdqu array_b(%rip), %ymm1
# 2. 执行整数 SIMD 加法
vpaddd %ymm0, %ymm1, %ymm2 # ymm2 = ymm0 + ymm1, 结果为 11, 22, 33, 44, 55, 66, 77, 88
# 3. 将 8 个结果存回内存
vmovdqa %ymm2, result(%rip) # 对齐版本的 mov
这个程序定义了两个储存 8 个 32 位 int 整数的数组:array_a和array_b,把他们加载到ymm0和ymm1,求和结果放入ymm2,再将结果传回内存。
汇编 + 链接 + gdb:
as -g -o simd_int.o simd_int.s
ld -o simd_int simd_int.o
gdb ./simd_int
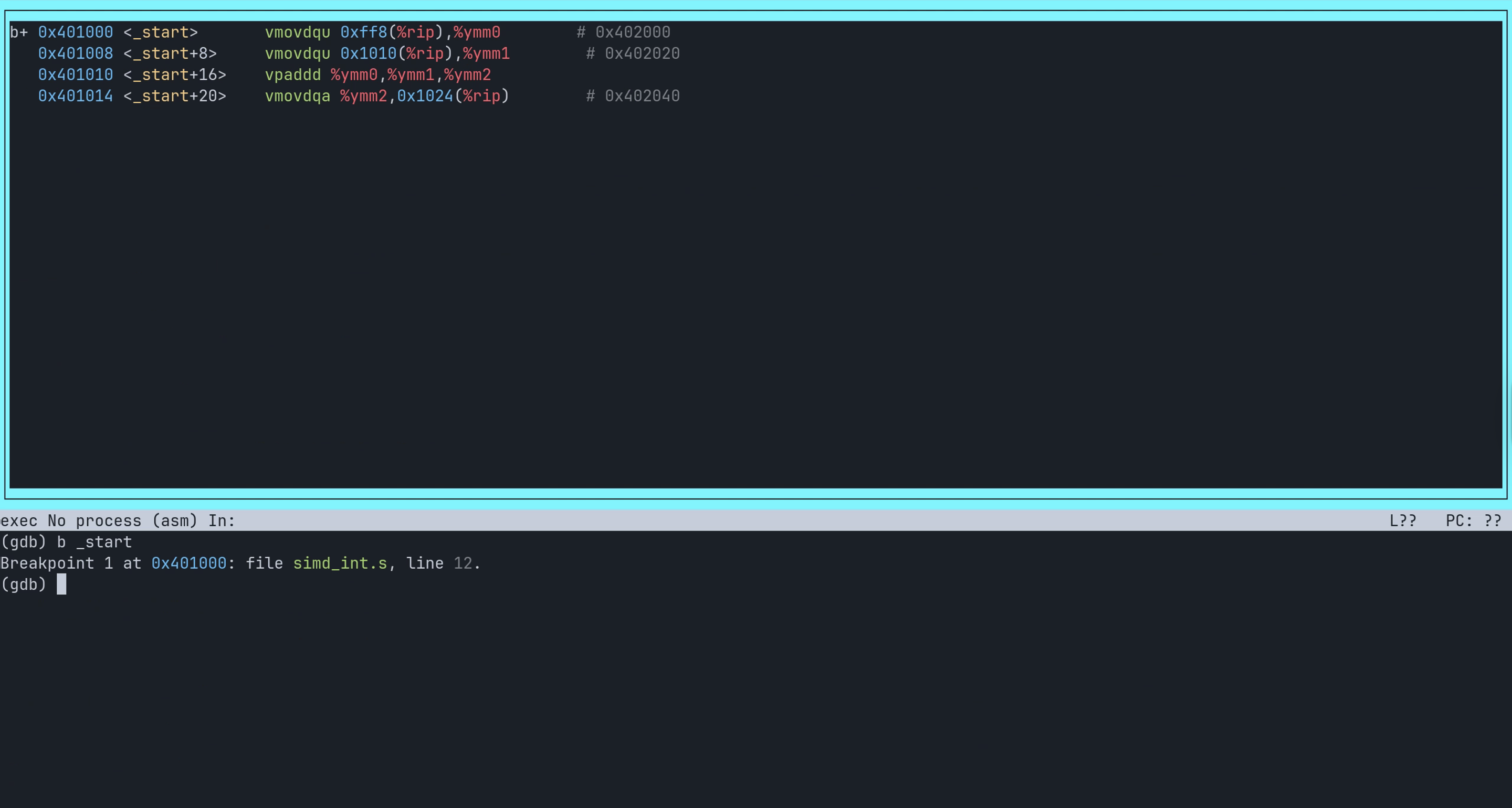
在 gdb 中只有四条指令:
vmovdqu 0xff8(%rip), %ymm0
vmovdqu 0x1010(%rip), %ymm1
vpaddd %ymm0, %ymm1, %ymm2
vmovdqa %ymm2, 0x1024(%rip)
0xff8(%rip)是汇编器 as 计算的 array_a 的地址,0x1010(%rip)则是 array_b 的地址,而0x1024(%rip)是结果 result 的地址。先执行第一条指令,看看vmovdqu是如何一次性搬运 8 个整数到%ymm0的:
(gdb) b _start
Breakpoint 1 at 0x401000: file simd_int.s, line 12.
(gdb) r
Breakpoint 1, _start () at simd_int.s:12
(gdb) si # 执行 vmovdqu array_a(%rip), %ymm0
此时第一条指令执行完毕,array_a已被存入%ymm0,我们用info register ymm0来查看%ymm0的数据:
(gdb) info register ymm0
ymm0 {v16_bfloat16 = {0xa, 0x0, 0x14, 0x0, 0x1e, 0x0, 0x28, 0x0, 0x32, 0x0, 0x3c, 0x0, 0x46, 0x0, 0x50, 0x0}, v16_half = {0xa, 0x0, 0x14, 0x0, 0x1e, 0x0, 0x28, 0x0, 0x32, 0x0, 0x3c, 0x0, 0x46, 0x0, 0x50, 0x0}, v8_float = {0xa, 0x14, 0x1e, 0x28, 0x32, 0x3c, 0x46, 0x50}, v4_double = {0x140000000a, 0x280000001e, 0x3c00000032, 0x5000000046}, v32_int8 = {0xa, 0x0, 0x0, 0x0, 0x14, 0x0, 0x0, 0x0, 0x1e, 0x0, 0x0, 0x0, 0x28, 0x0, 0x0, 0x0, 0x32, 0x0, 0x0, 0x0, 0x3c, 0x0, 0x0, 0x0, 0x46, 0x0, 0x0, 0x0, 0x50, 0x0, 0x0, 0x0}, v16_int16 = {0xa, 0x0, 0x14, 0x0, 0x1e, 0x0, 0x28, 0x0, 0x32, 0x0, 0x3c, 0x0, 0x46, 0x0, 0x50, 0x0}, v8_int32 = {0xa, 0x14, 0x1e, 0x28, 0x32, 0x3c, 0x46, 0x50}, v4_int64 = {0x140000000a, 0x280000001e, 0x3c00000032, 0x5000000046}, v2_int128 = {0x280000001e000000140000000a, 0x50000000460000003c00000032}}
对于%ymm0硬件来说,它只是一个储存 256 位数据的寄存器,但对于 gdb 来说,这 256 位有非常多不同可能的表示,他可能是 4 个 64位的 double ,可能是 8 个 32 位的 int ,也可能是 16 个 16 位的 short 。所以 gdb 把他定义成一个 union,将这 256 位数据按照所有可能的数据类型都翻译了一遍。我们需要的是 8 个32 位 int 的解读,只需关注这一段:
v8_int32 = {0xa, 0x14, 0x1e, 0x28, 0x32, 0x3c, 0x46, 0x50}
他们就是 10,20,30… 的十六进制表示。由于 ymm0 本质上是一个 union,所以更好的方式是用p直接提取我们需要的解释:
(gdb) p $ymm0.v8_int32
$1 = {10, 20, 30, 40, 50, 60, 70, 80}
现在array_a已经加载进寄存器了,接下来是array_b:
(gdb) si # 执行 vmovdqu array_b(%rip), %ymm1
(gdb) p $ymm1.v8_int32
$2 = {1, 2, 3, 4, 5, 6, 7, 8}
两个寄存器已经准备就绪,执行vpaddd:
(gdb) si # 执行 vpaddd %ymm0, %ymm1, %ymm2
(gdb) p $ymm2.v8_int32
$3 = {11, 22, 33, 44, 55, 66, 77, 88}
可以看到ymm2已经成功得到了结果。
最后一步:把结果存入内存
(gdb) si # 执行 vmovdqa %ymm2, result(%rip)
回顾result的地址是0x1024(%rip)。我们直接访问这段内存,看看数据有没有被成功存入:
(gdb) x/8 0x1024 + $rip
0x402040: 11 22 33 44
0x402050: 55 66 77 88
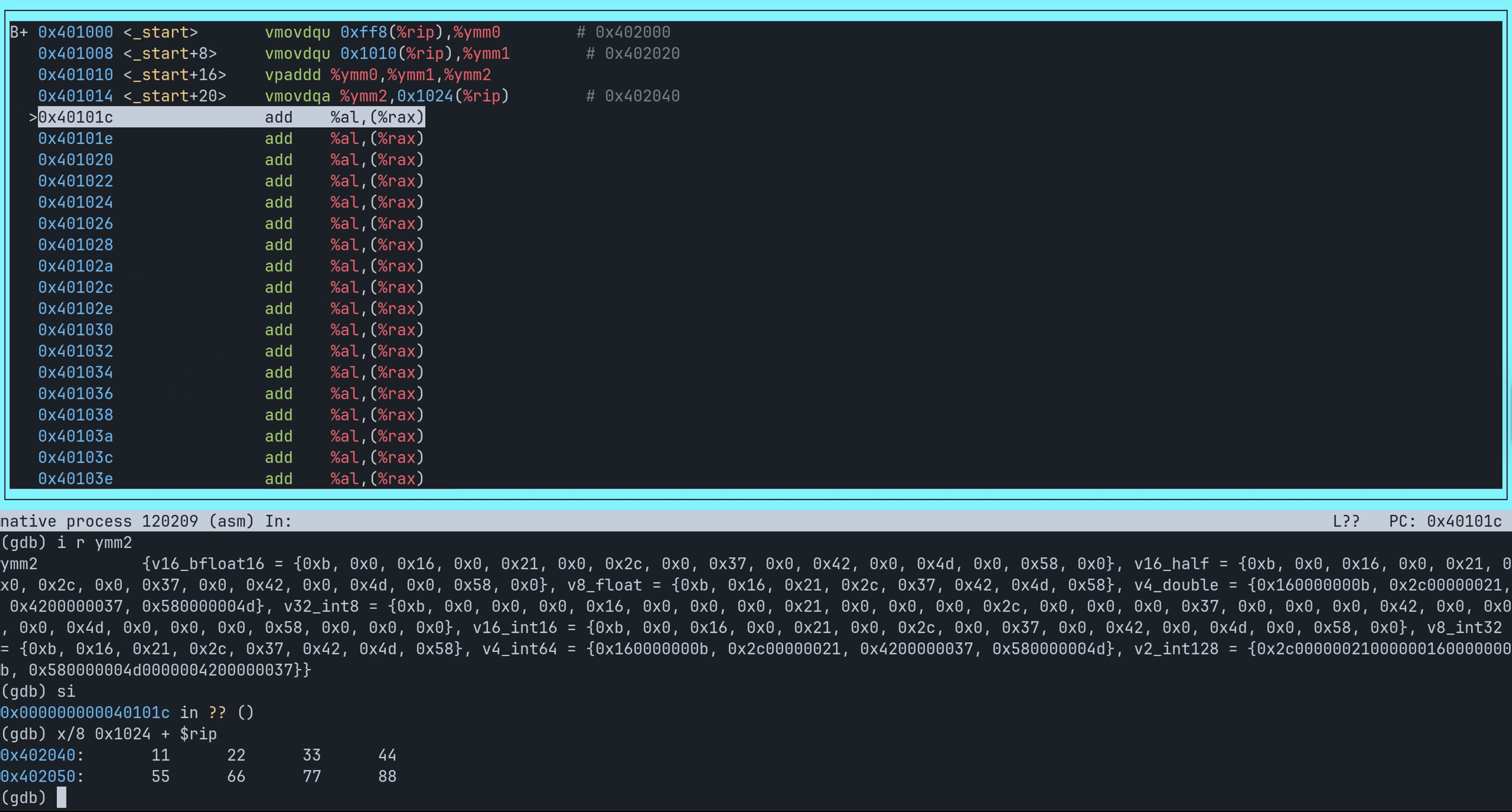
成功的在内存中读取到了正确答案。
但是在生产环境中很少直接写汇编程序。这就引出了一个经典问题:编译器会不会帮我们向量化?
以一开始的例子为例:
// add.c
#define NUM_ELEMS ((1 << 16) + 10)
void add(int *sum, int *a, int *b) {
for (int i = 0; i < NUM_ELEMS; i++) {
sum[i] = a[i] + b[i];
}
}
用 gcc 开启 O3 优化:
gcc -S -O3 add.c
循环内的代码是这样的:
.L3:
movdqu (%rsi,%rax), %xmm0
movdqu (%rdx,%rax), %xmm2
paddd %xmm2, %xmm0
movups %xmm0, (%rdi,%rax)
addq $16, %rax
cmpq $262176, %rax
jne .L3
movq 262176(%rsi), %xmm0
movq 262176(%rdx), %xmm1
paddd %xmm1, %xmm0
movq %xmm0, 262176(%rdi)
ret
gcc 确实帮我们实现了向量化,但使用的是 SSE 的%xmm,而非宽度更大的%ymm。这是因为 gcc 需要保证所有硬件的兼容性,目前并非所有 x86 CPU 都支持 AVX2。为了让 gcc 生成 AVX2 的向量化汇编,我们需要用-mavx2或-march=native显式指定架构:
gcc -S -mavx2 -O3 add.c
.L3:
vmovdqu (%rdx,%rax), %ymm0
vpaddd (%rsi,%rax), %ymm0, %ymm0
vmovdqu %ymm0, (%rdi,%rax)
addq $32, %rax
cmpq $262176, %rax
jne .L3
vmovq 262176(%rsi), %xmm0
vmovq 262176(%rdx), %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vmovq %xmm0, 262176(%rdi)
vzeroupper
ret
熟悉的 AVX 指令又回来了。
编译器的优化已经十分强大,能应付 90% 的情况。但为了不出错,编译器采取的策略一直比较保守,有可能放弃本有潜力优化的空间。比如别名分析,当它不能确定两个指针是否指向同一块内存时,会选择安全的标量代码。这时,就需要我们手写 SIMD 指令。一种方法是内联汇编,直接操作汇编语言的效率自然是最高的,但是需要打破抽象层,而且在不同 ISA 的机器上无法移植。为了解决这个问题,Intel 在推出第一代 SIMD 指令集 MMX (Multi-Media eXtension) 时,和微软合作引入了 Intrinsic Functions。
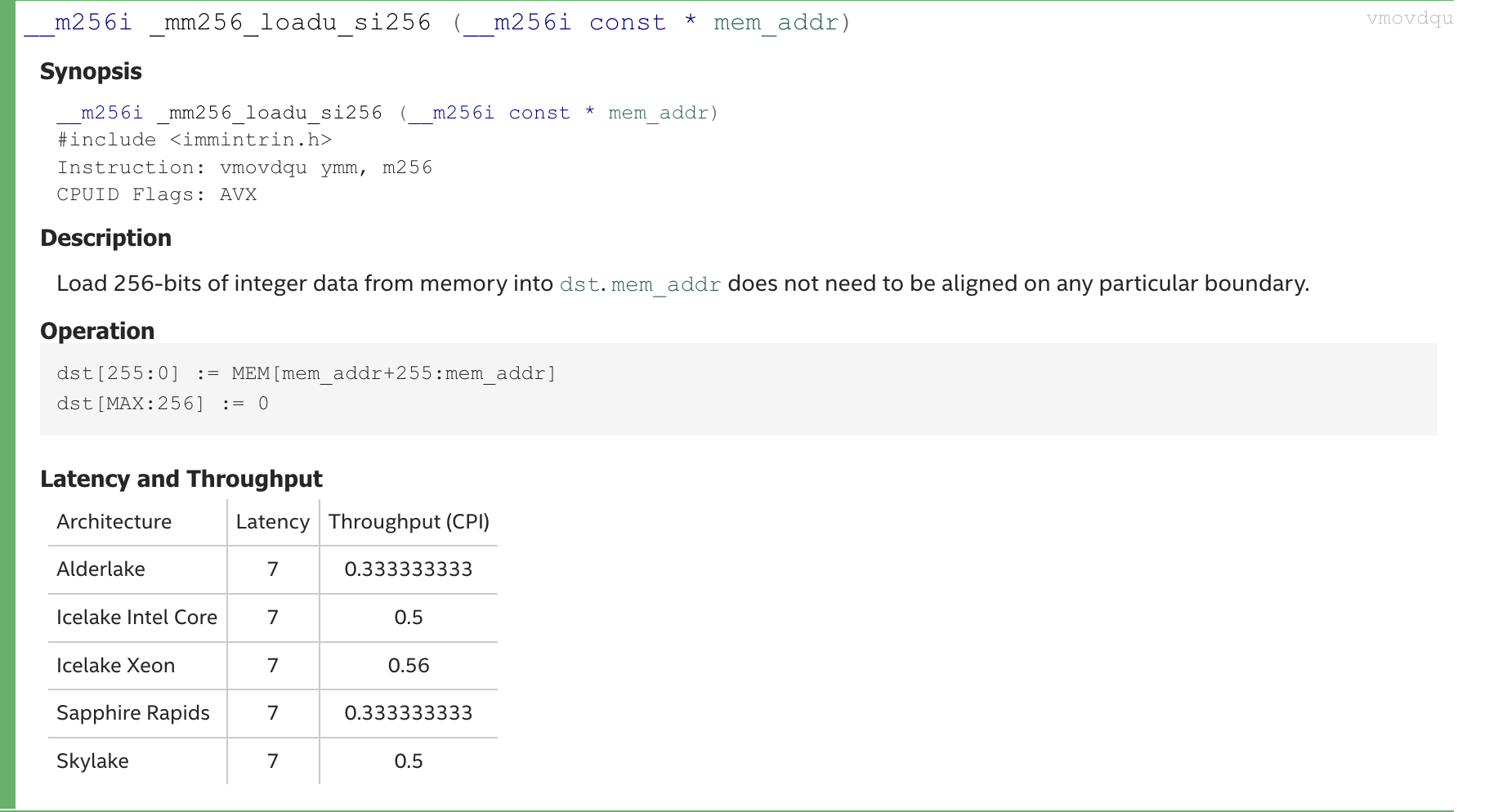
Intrinsic 提供了 SIMD 汇编的抽象,作为 C 语言的函数出现,但编译器会直接将其映射为对应的汇编指令。比如,%ymm寄存器代表的 256 位向量在 Intrinsic 中被抽象成了一个数据类型__m256i ,这是 AVX2 Intrinsic 的基石。vmovdqu被抽象成一个函数_mm256_loadu_si256,它接受一个内存地址,将其后 256 位的数据移动到%ymm寄存器,作为一个__m256i类型的值:
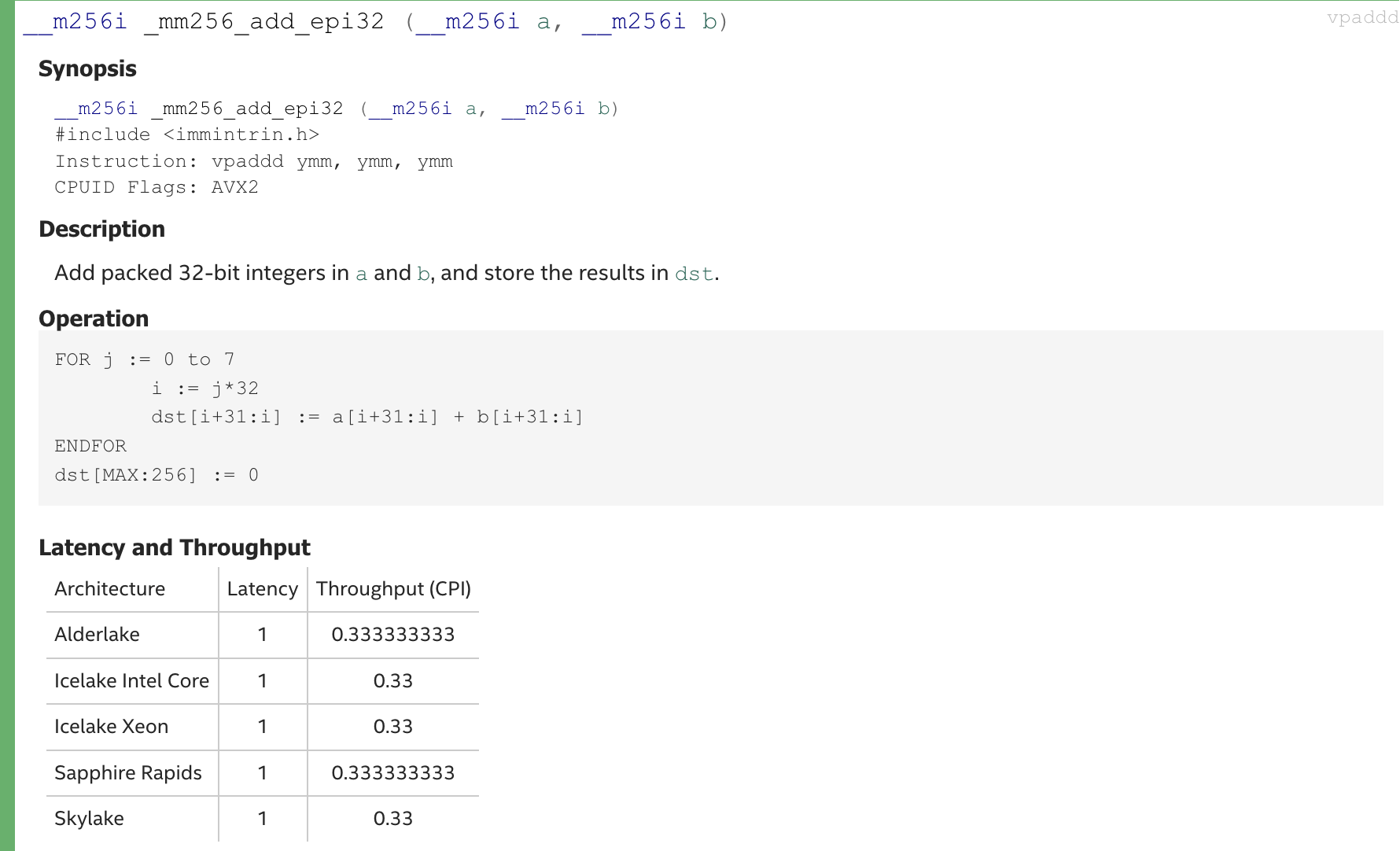
vpaddd被抽象成函数_mm256_add_epi32它接受两个__m256i,返回它们的向量和:
x86 所有的 Intrinsic 都可以在 Intel Intrinsic Guide 中找到。
那么,SIMD 究竟可以优化到什么程度?
考虑以下函数:
// Source: cs61c.org
// sum.c
#define NUM_ELEMS ((1 << 16) + 10)
#define OUTER_ITERATIONS (1 << 14)
long long int sum(int vals[NUM_ELEMS]) {
clock_t start = clock();
long long int sum = 0;
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++) {
for(unsigned int i = 0; i < NUM_ELEMS; i++) {
if(vals[i] >= 128) {
sum += vals[i];
}
}
}
clock_t end = clock();
printf("Time taken: %Lf s\n", (long double)(end - start) / CLOCKS_PER_SEC);
return sum;
}
// main function
这个函数对一个长度为NUM_ELEMS的数组中所有大于等于 128 的数求和,总共求和OUTER_ITERATIONS次。
用 O0 关闭优化,看看在我这颗 12700KF 上需要多长时间执行:
gcc -O0 -mavx2 sum.c -o sum
./sum
Starting generate array
Starting naive sum
Time taken: 3.990946 s
The answer is 103161741312
用了近 4 秒。
我们用 AVX2 的 Intrinsic 对函数进行优化:
// sum_simd.c
#define NUM_ELEMS ((1 << 16) + 10)
#define OUTER_ITERATIONS (1 << 14)
long long int sum_simd(int vals[NUM_ELEMS]) {
clock_t start = clock();
// 将 256 位阈值向量切成 8 份,每份填入整数 127,用于代替 if
// [127, 127, 127, 127, 127, 127, 127, 127]
__m256i threshold = _mm256_set1_epi32(127);
long long int final_sum = 0;
for (unsigned int w = 0; w < OUTER_ITERATIONS; w++) {
// 初始化局部累加向量
__m256i sum = _mm256_setzero_si256();
// 向量化主循环:步长为 8(因为一个寄存器装 8 个 int)
// (NUM_ELEMS & ~7) 的作用是将数组长度向下取 8 的倍数,等于 NUM_ELEMS / 8 * 8
for (unsigned int i = 0; i < (NUM_ELEMS & ~7); i += 8) {
// 一次性搬运 8 个整数到 vals_vec 寄存器
__m256i vals_vec = _mm256_loadu_si256((__m256i *) (vals + i));
// 比较生成掩码:执行 vals_vec > 127
// 如果条件成立,对应位置变为全 1 (0xFFFFFFFF);否则全 0 (0x00000000)
__m256i mask = _mm256_cmpgt_epi32(vals_vec, threshold);
// vals_vec = vals_vec & mask
// 实现"只有大于 127 的数才参与后续加法"
vals_vec = _mm256_and_si256(vals_vec, mask);
// sum = sum + vals_vec
sum = _mm256_add_epi32(sum, vals_vec);
}
// 将寄存器里的 8 个部分和导出到普通数组 temp 中
int temp[8];
_mm256_storeu_si256((__m256i *) temp, sum);
// 将 8 个部分和加到最终结果 final_sum
for (unsigned int i = 0; i < 8; i++) {
final_sum += temp[i];
}
// 处理数组末尾不足 8 个的部分,即 NUM_ELEMS & ~7 截断后剩下的元素
for (unsigned int i = NUM_ELEMS & ~7; i < NUM_ELEMS; i++) {
if (vals[i] >= 128) {
final_sum += vals[i];
}
}
}
clock_t end = clock();
printf("Time taken: %Lf s\n", (long double)(end - start) / CLOCKS_PER_SEC);
return final_sum;
}
// main function
gcc -O0 -mavx2 sum_simd.c -o sum_simd
./sum_simd
Starting generate array
Starting simd sum
Time taken: 0.393570 s
The answer is 103161741312
答案和 sum 一样,因为程序没有显式调用 srand() 设种子,所以在同一实现下通常会得到相同的伪随机序列,这也侧面印证了我们的计算是正确的。而时间用了近 0.4 秒,是 sum 的十分之一,比 SIMD 带来的 8 倍效率还要快。额外的 1.5-2x 提升来自用位运算掩码替代条件分支,消除了分支预测失败的开销。
我们用perf stat详细的看看 sum 运行的情况:
perf stat ./sum
Starting generate array
Starting naive sum
Time taken: 3.930958 s
The answer is 103161741312
Performance counter stats for './sum':
0 context-switches:u # 0.0 cs/sec cs_per_second
0 cpu-migrations:u # 0.0 migrations/sec migrations_per_second
126 page-faults:u # 32.0 faults/sec page_faults_per_second
3,938.66 msec task-clock:u # 1.0 CPUs CPUs_utilized
495,185,828 cpu_core/branch-misses/u # 23.0 % branch_miss_rate (99.72%)
2,151,442,727 cpu_core/branches/u # 546.2 M/sec branch_frequency (99.72%)
19,663,072,544 cpu_core/cpu-cycles/u # 5.0 GHz cycles_frequency (99.72%)
14,500,973,667 cpu_core/instructions/u # 0.7 instructions insn_per_cycle (99.72%)
334,563,943 cpu_atom/branch-misses/u # 23.1 % branch_miss_rate (0.15%)
1,376,773,280 cpu_atom/branches/u # 349.6 M/sec branch_frequency (0.15%)
8,923,766,423 cpu_atom/cpu-cycles/u # 2.3 GHz cycles_frequency (0.15%)
6,682,252,453 cpu_atom/instructions/u # 1.0 instructions insn_per_cycle (0.15%)
TopdownL1 (cpu_core) # 56.3 % tma_bad_speculation
# 23.0 % tma_frontend_bound (99.72%)
# 8.2 % tma_backend_bound
# 12.5 % tma_retiring (99.72%)
TopdownL1 (cpu_atom) # 7.6 % tma_backend_bound (0.15%)
# 44.9 % tma_frontend_bound (0.15%)
# 13.2 % tma_bad_speculation
# 34.4 % tma_retiring (0.15%)
3.940752101 seconds time elapsed
3.934609000 seconds user
0.000980000 seconds sys
Branch miss 数达到了 334,563,943 次,分支预测失败率达到了 23%,P 核的 IPC 只有可怜的 0.7。Bad speculation 有 56.3%,CPU 超过一半的时间都在做无用功。
再来看看 sum_simd 的情况:
perf stat ./sum_simd
Starting generate array
Starting simd sum
Time taken: 0.380635 s
The answer is 103161741312
Performance counter stats for './sum_simd':
0 context-switches:u # 0.0 cs/sec cs_per_second
0 cpu-migrations:u # 0.0 migrations/sec migrations_per_second
125 page-faults:u # 326.0 faults/sec page_faults_per_second
383.43 msec task-clock:u # 1.0 CPUs CPUs_utilized
25,382 cpu_core/branch-misses/u # 0.0 % branch_miss_rate
135,624,062 cpu_core/branches/u # 353.7 M/sec branch_frequency
1,889,389,397 cpu_core/cpu-cycles/u # 4.9 GHz cycles_frequency
4,838,841,161 cpu_core/instructions/u # 2.6 instructions insn_per_cycle
TopdownL1 (cpu_core) # 0.0 % tma_bad_speculation
# 2.4 % tma_frontend_bound
# 53.7 % tma_backend_bound
# 43.9 % tma_retiring
0.384798731 seconds time elapsed
0.383394000 seconds user
0.000975000 seconds sys
由于循环中没有使用 if 指令,分支预测失败率为可以忽略不计的 0%,IPC 现在提升到了 2.6,指令数也从 145 亿减少到了 48 亿,近三分之一。SIMD + 比较掩码给了我们 10 倍的性能提升。
这还远远不是优化的极限。作为能解决 90% 优化问题的方案,我们看看编译器的优化效率如何:
gcc -O3 -mavx2 sum.c -o sum_o3
./sum_o3
Starting generate array
Starting naive sum
Time taken: 0.161733 s
The answer is 103161741312
O3 优化的 naive 版本花费 0.16 秒,比 O0 的 SIMD 版本还要快两倍以上。为什么会这样?
揭示答案的自然还是汇编代码:
objdump -d sum_simd | less
以下是部分内侧循环的指令:
vmovdqu (%rax),%ymm0
vmovdqa %ymm0,-0x170(%rbp)
vmovdqa -0x170(%rbp),%ymm0
vmovdqa %ymm0,-0xb0(%rbp)
vmovdqa -0x190(%rbp),%ymm0
vmovdqa %ymm0,-0x90(%rbp)
vmovdqa -0xb0(%rbp),%ymm0
vmovdqa -0x90(%rbp),%ymm1
vpcmpgtd %ymm1,%ymm0,%ymm0
vmovdqa %ymm0,-0x150(%rbp)
vmovdqa -0x170(%rbp),%ymm0
...
在 O0 的条件下,编译器不会积极做寄存器分配和指令级优化,虽然 Intrinsic 仍会展开为对应指令,但中间结果常被频繁溢出到栈上再读回寄存器,于是出现了大量多余的vmovdqa。这才是效率低下最根本的原因。而 O3 版本,即使是最 naive 的方法,也不会出现此类问题:
objdump -d sum_o3 | less
vpbroadcastd (%rax),%ymm1 # broadcast 到所有通道
add $0x4,%rax # 每次加 4,说明一次只处理一个 32 位元素
vpcmpgtd %ymm6,%ymm1,%ymm0
vpmovsxdq %xmm1,%ymm3
vextracti128 $0x1,%ymm1,%xmm1
vpmovsxdq %xmm1,%ymm1
vpmovsxdq %xmm0,%ymm2
vextracti128 $0x1,%ymm0,%xmm0
vpmovsxdq %xmm0,%ymm0
vpand %ymm3,%ymm2,%ymm2
vpand %ymm1,%ymm0,%ymm0
vpaddq %ymm2,%ymm4,%ymm4
vpaddq %ymm0,%ymm5,%ymm5
cmp %rax,%rdx
jne 1380 <sum+0x80>
add $0x1,%ecx
cmp $0x800,%ecx
jne 133f <sum+0x3f>
...
没有任何存数据到内存的无用操作,所有计算均在寄存器中进行,最终使我们的效率提升了两倍。
但就算是 O3,这里也做了一个保守的决定。回顾vals的数据类型是 32 位的int,而最终和的数据类型是 64 位的long long int,为了防止溢出,gcc 实际上每次迭代只处理一个元素,用 vpmovsxdq 将 32 位扩展到 64 位后再用 vpaddq 累加,而vpbroadcastd 将该元素广播到各通道以配合后续的 SIMD 扩展操作。如果不考虑溢出的情况,O3 的版本是次优的,编译器的局限性就体现出来了。
为什么有编译器优化,还需要手写 Intrinsic 的意义就在这里。对手写 Intrinsic 的版本进行 O3 优化:
gcc -O3 -mavx2 sum_simd.c -o sum_simd_o3
./sum_simd_o3
Starting generate array
Starting simd sum
Time taken: 0.065357 s
The answer is 103161741312
O3 版本的 sum_simd 花费 0.065 秒完成所有计算,比 O3 版本的 sum 快了近三倍。观察 sum_simd_o3 的汇编,没有因害怕溢出而进行的保守操作,只有纯粹的 SIMD:
objdump -d sum_simd_o3 | less
vmovdqu (%rax),%ymm0
add $0x20,%rax
vpcmpgtd %ymm3,%ymm0,%ymm2
vpand %ymm2,%ymm0,%ymm0
vpaddd %ymm1,%ymm0,%ymm0
vmovdqa %ymm0,%ymm1
cmp %rdx,%rax
jne 15a0 <sum_simd+0x60>
...
最后看看 sum_simd_o3 的性能如何:
perf stat ./sum_simd_o3
Starting generate array
Starting simd sum
Time taken: 0.046438 s
The answer is 103161741312
Performance counter stats for './sum_simd_o3':
0 context-switches:u # 0.0 cs/sec cs_per_second
0 cpu-migrations:u # 0.0 migrations/sec migrations_per_second
124 page-faults:u # 2527.5 faults/sec page_faults_per_second
49.06 msec task-clock:u # 0.9 CPUs CPUs_utilized
25,161 cpu_core/branch-misses/u # 0.0 % branch_miss_rate (99.91%)
135,448,448 cpu_core/branches/u # 2760.9 M/sec branch_frequency (99.91%)
199,548,588 cpu_core/cpu-cycles/u # 4.1 GHz cycles_frequency (99.91%)
1,079,758,372 cpu_core/instructions/u # 5.4 instructions insn_per_cycle (99.91%)
0 cpu_atom/branch-misses/u # nan % branch_miss_rate (0.09%)
0 cpu_atom/branches/u # 0.0 M/sec branch_frequency (0.09%)
0 cpu_atom/cpu-cycles/u # 0.0 GHz cycles_frequency (0.09%)
0 cpu_atom/instructions/u # nan instructions insn_per_cycle (0.09%)
TopdownL1 (cpu_core) # 0.4 % tma_bad_speculation
# 4.3 % tma_frontend_bound (99.91%)
# 16.4 % tma_backend_bound
# 78.9 % tma_retiring (99.91%)
0.050319023 seconds time elapsed
0.048218000 seconds user
0.001995000 seconds sys
IPC 达到了 5.4,是个非常不错的数字,而 Retiring 达到了 78.9%,绝大部分时钟周期都在做有用的运算。指令数也减少到了十亿左右,是 O0 版本的将近四分之一。如果想更进一步榨干硬件的性能,可以对 Intrinsic 函数也应用循环展开,但对于一般的优化工作,学会串行使用 Intrinsic 已经足够了。
以下是基于同一台机器(12700KF)对前文分析的总结:
| 版本 | 编译选项 | 手写 SIMD | Time taken (s) | 相对 sum -O0 加速比 |
|---|---|---|---|---|
sum | -O0 -mavx2 | 否 | 3.990946 | 1.0x |
sum_simd | -O0 -mavx2 | 是(AVX2 Intrinsic) | 0.393570 | 10.1x |
sum_o3 | -O3 -mavx2 | 否 | 0.161733 | 24.7x |
sum_simd_o3 | -O3 -mavx2 | 是(AVX2 Intrinsic) | 0.065357 | 61.1x |
并行计算是个很有趣的领域,有点像超市买一送多的优惠券,一次性给我们带来好几倍的免费性能提升。但代价也是有的,比如要求数据对齐,或者功耗过高会导致降频,正是这个原因导致我 12700KF 上的 AVX-512 被砍了。在复杂的逻辑业务中,编译器的优化 is all you need,但是在图形处理和深度学习领域,就好好的享受多件折上折吧。